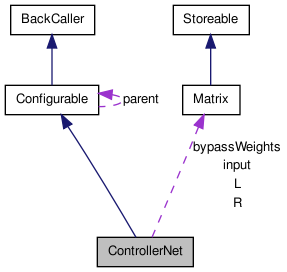
ControllerNet Class Reference
multi layer neural network with configurable activation functions and propagation and projection methods suitable for homeokinesis controller More...
#include <controllernet.h>
Inherits Configurable.
Public Member Functions | |
| ControllerNet (const std::vector< Layer > &layers, bool useBypass=false) | |
| virtual | ~ControllerNet () |
| virtual void | init (unsigned int inputDim, unsigned int outputDim, double unit_map=0.0, double rand=0.2, RandGen *randGen=0) |
| initialisation of the network with the given number of input and output units. | |
| virtual const matrix::Matrix | process (const matrix::Matrix &input) |
| passive processing of the input. | |
| virtual const matrix::Matrix | processX (const matrix::Matrix &input, const matrix::Matrix &injection, unsigned int injectInLayer) |
| like process just with the opportunity to overwrite the activation of a specific layer | |
| virtual void | damp (double damping) |
| damps the weights and the biases by multiplying (1-damping) | |
| virtual const matrix::Matrix & | response () const |
| response matrix of neural network (for current activation, see process)
with | |
| virtual matrix::Matrix | responsePart (int from, int to) const |
| like response, just that only a range of layers is considered The Bypass is not considered here. | |
| virtual const matrix::Matrix & | responseLinear () const |
| linear response matrix of neural network
| |
| virtual const matrix::Matrix | backpropagation (const matrix::Matrix &error, matrix::Matrices *errors=0, matrix::Matrices *zetas=0) const |
| backpropagation of vector error through network. | |
| virtual const matrix::Matrix | backpropagationX (const matrix::Matrix &error, matrix::Matrices *errors=0, matrix::Matrices *zetas=0, int startWithLayer=-1) const |
| like backpropagation but with special features: we can start from any layer and the bypass-discounting can be used (see disseration Georg Martius) WARNING: the errors and zetas above the `startWithLayer' are undefined | |
| virtual const matrix::Matrix | backprojection (const matrix::Matrix &error, matrix::Matrices *errors=0, matrix::Matrices *zetas=0) const |
| backprojection of vector error through network. | |
| virtual const matrix::Matrix | forwardpropagation (const matrix::Matrix &error, matrix::Matrices *errors=0, matrix::Matrices *zetas=0) const |
| forwardpropagation of vector error through network. | |
| virtual const matrix::Matrix | forwardprojection (const matrix::Matrix &error, matrix::Matrices *errors=0, matrix::Matrices *zetas=0) const |
| forwardprojection of vector error through network. | |
| virtual unsigned int | getInputDim () const |
| returns the number of input neurons | |
| virtual unsigned int | getOutputDim () const |
| returns the number of output neurons | |
| virtual const matrix::Matrix & | getLayerOutput (int layer) const |
| returns activation of the given layer. | |
| virtual unsigned int | getLayerNum () const |
| virtual const Layer & | getLayer (unsigned int layer) const |
| layers 0 is the first hidden layer | |
| virtual Layer & | getLayer (unsigned int layer) |
| layers 0 is the first hidden layer | |
| virtual const matrix::Matrix & | getWeights (int to_layer) const |
| weight matrix 0 connects input with the first hidden layer Negative values count from the end (-1 is the last layer) | |
| virtual matrix::Matrix & | getWeights (int to_layer) |
| weight matrix 0 connects input with the first hidden layer Negative values count from the end (-1 is the last layer) | |
| virtual const matrix::Matrix & | getByPass () const |
| virtual matrix::Matrix & | getByPass () |
| virtual const matrix::Matrix & | getBias (int of_layer) const |
| Note: layers 0 is the first hidden layer Negative values count from the end (-1 is the last layer). | |
| virtual matrix::Matrix & | getBias (int of_layer) |
| Note: layers 0 is the first hidden layer Negative values count from the end (-1 is the last layer). | |
| bool | store (FILE *f) const |
| stores the layer binary into file stream | |
| bool | restore (FILE *f) |
| restores the layer binary from file stream | |
| bool | write (FILE *f) const |
| writes the layer ASCII into file stream (not in the storable interface) | |
Protected Member Functions | |
| virtual void | calcResponseIntern () |
Protected Attributes | |
| std::vector< Layer > | layers |
| std::vector< matrix::Matrix > | weights |
| std::vector< matrix::Matrix > | bias |
| bool | useBypass |
| matrix::Matrix | bypassWeights |
| matrix::Matrix | input |
| matrix::Matrices | y |
| matrix::Matrices | z |
| matrix::Matrices | gp |
| matrix::Matrix | L |
| matrix::Matrix | R |
| double | lambda |
| bool | initialised |
Detailed Description
multi layer neural network with configurable activation functions and propagation and projection methods suitable for homeokinesis controller
Constructor & Destructor Documentation
| ControllerNet | ( | const std::vector< Layer > & | layers, | |
| bool | useBypass = false | |||
| ) |
- Parameters:
-
layers Layer description (the input layer is not specified (always linear)) useBypass if true, then a connection from input to output layer is included
| virtual ~ControllerNet | ( | ) | [inline, virtual] |
Member Function Documentation
| virtual const matrix::Matrix backprojection | ( | const matrix::Matrix & | error, | |
| matrix::Matrices * | errors = 0, |
|||
| matrix::Matrices * | zetas = 0 | |||
| ) | const [virtual] |
backprojection of vector error through network.
The storage for the intermediate values (errors, zetas) do not need to be given. The errors(layerwise) are at the output of the neurons (index 0 is at the input level, output of layer 0 has index 1 and so on) The zetas(layerwise) are the values inside the neurons that arise when backprojecting the error signal. (zeta[0] is at layer 0)
- Returns:
- errors[0] (result of backprojecting)
| virtual const matrix::Matrix backpropagation | ( | const matrix::Matrix & | error, | |
| matrix::Matrices * | errors = 0, |
|||
| matrix::Matrices * | zetas = 0 | |||
| ) | const [virtual] |
backpropagation of vector error through network.
The storage for the intermediate values (errors, zetas) do not need to be given. The errors(layerwise) are at the output of the neurons (index 0 is at the input level, output of layer 0 has index 1 and so on) The zetas(layerwise) are the values inside the neurons that arise when backpropagating the error signal. (zeta[0] is at layer 0)
- Returns:
- errors[0] (result of backpropagation)
| virtual const matrix::Matrix backpropagationX | ( | const matrix::Matrix & | error, | |
| matrix::Matrices * | errors = 0, |
|||
| matrix::Matrices * | zetas = 0, |
|||
| int | startWithLayer = -1 | |||
| ) | const [virtual] |
like backpropagation but with special features: we can start from any layer and the bypass-discounting can be used (see disseration Georg Martius) WARNING: the errors and zetas above the `startWithLayer' are undefined
- Parameters:
-
startWithLayer the error is clamped at this layer and the processing starts there (-1: output layer)
- See also:
- backpropagation
| void calcResponseIntern | ( | ) | [protected, virtual] |
| void damp | ( | double | damping | ) | [virtual] |
damps the weights and the biases by multiplying (1-damping)
| virtual const matrix::Matrix forwardprojection | ( | const matrix::Matrix & | error, | |
| matrix::Matrices * | errors = 0, |
|||
| matrix::Matrices * | zetas = 0 | |||
| ) | const [virtual] |
forwardprojection of vector error through network.
The storage for the intermediate values (errors, zetas) do not need to be given. The errors(layerwise) are at the output of the neurons (index 0 is at the input level = error, output of layer 0 has index 1 and so on) The zetas(layerwise) are the values inside the neurons that arise when forwardprojecting the error signal. (zeta[0] is at layer 0)
- Returns:
- errors[layernum] (result of forwardprojection)
| virtual const matrix::Matrix forwardpropagation | ( | const matrix::Matrix & | error, | |
| matrix::Matrices * | errors = 0, |
|||
| matrix::Matrices * | zetas = 0 | |||
| ) | const [virtual] |
forwardpropagation of vector error through network.
The storage for the intermediate values (errors, zetas) do not need to be given. The errors(layerwise) are at the output of the neurons (index 0 is at the input level = error, output of layer 0 has index 1 and so on) The zetas(layerwise) are the values inside the neurons that arise when forwardpropagate the error signal. (zeta[0] is at layer 0)
- Returns:
- errors[layernum] (result of forwardpropagation)
| virtual matrix::Matrix& getBias | ( | int | of_layer | ) | [inline, virtual] |
Note: layers 0 is the first hidden layer Negative values count from the end (-1 is the last layer).
| virtual const matrix::Matrix& getBias | ( | int | of_layer | ) | const [inline, virtual] |
Note: layers 0 is the first hidden layer Negative values count from the end (-1 is the last layer).
| virtual matrix::Matrix& getByPass | ( | ) | [inline, virtual] |
| virtual const matrix::Matrix& getByPass | ( | ) | const [inline, virtual] |
| virtual unsigned int getInputDim | ( | ) | const [inline, virtual] |
returns the number of input neurons
| virtual Layer& getLayer | ( | unsigned int | layer | ) | [inline, virtual] |
layers 0 is the first hidden layer
| virtual const Layer& getLayer | ( | unsigned int | layer | ) | const [inline, virtual] |
layers 0 is the first hidden layer
| virtual unsigned int getLayerNum | ( | ) | const [inline, virtual] |
| virtual const matrix::Matrix& getLayerOutput | ( | int | layer | ) | const [inline, virtual] |
returns activation of the given layer.
Layer 0 is the first hidden layer. Negative values count from the end (-1 is the last layer)
| virtual unsigned int getOutputDim | ( | ) | const [inline, virtual] |
returns the number of output neurons
| virtual matrix::Matrix& getWeights | ( | int | to_layer | ) | [inline, virtual] |
weight matrix 0 connects input with the first hidden layer Negative values count from the end (-1 is the last layer)
| virtual const matrix::Matrix& getWeights | ( | int | to_layer | ) | const [inline, virtual] |
weight matrix 0 connects input with the first hidden layer Negative values count from the end (-1 is the last layer)
| void init | ( | unsigned int | inputDim, | |
| unsigned int | outputDim, | |||
| double | unit_map = 0.0, |
|||
| double | rand = 0.2, |
|||
| RandGen * | randGen = 0 | |||
| ) | [virtual] |
initialisation of the network with the given number of input and output units.
The dimensionality of the ouputlayer is automatically adjusted.
- Parameters:
-
unit_map defines the approximate response of the network after initialisation (if unit_map=1 the weights are unit matrices). randGen pointer to random generator, if 0 an new one is used
| const Matrix process | ( | const matrix::Matrix & | input | ) | [virtual] |
passive processing of the input.
This has to be done before calling reponse, and the back/forward propagation/projection functions. The activations and the response matrix are stored internally.
| const Matrix processX | ( | const matrix::Matrix & | input, | |
| const matrix::Matrix & | injection, | |||
| unsigned int | injectInLayer | |||
| ) | [virtual] |
like process just with the opportunity to overwrite the activation of a specific layer
- Parameters:
-
injections the input that is clamped at layer injectInLayer injectInLayer the injection is clamped at this layer
| const Matrix & response | ( | ) | const [virtual] |
response matrix of neural network (for current activation, see process)
![\[ J_ij = \frac{\partial y_i}{\partial x_j} \]](form_0.png)
![\[ J = G_n' W_n G_{n-1}' W_{n-1} ... G_1' W_1 \]](form_1.png)
with 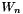 is the weight matrix of layer n and
is the weight matrix of layer n and 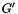 is a diagonal matrix with
is a diagonal matrix with 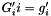 as values on the diagonal.
as values on the diagonal.
| const Matrix & responseLinear | ( | ) | const [virtual] |
linear response matrix of neural network
![\[ R = W_n W_{n-1} ... W_1 \]](form_5.png)
with is the weight matrix of layer n.
| Matrix responsePart | ( | int | from, | |
| int | to | |||
| ) | const [virtual] |
like response, just that only a range of layers is considered The Bypass is not considered here.
- Parameters:
-
from index of layer to start: -1 at input, 0 first hidden layer ... to index of layer to stop: -1: last layer, 0 first hidden layer ...
| bool restore | ( | FILE * | f | ) |
restores the layer binary from file stream
| bool store | ( | FILE * | f | ) | const |
stores the layer binary into file stream
| bool write | ( | FILE * | f | ) | const |
writes the layer ASCII into file stream (not in the storable interface)
Member Data Documentation
std::vector<matrix::Matrix> bias [protected] |
matrix::Matrix bypassWeights [protected] |
matrix::Matrices gp [protected] |
bool initialised [protected] |
matrix::Matrix input [protected] |
matrix::Matrix L [protected] |
double lambda [protected] |
matrix::Matrix R [protected] |
bool useBypass [protected] |
std::vector<matrix::Matrix> weights [protected] |
matrix::Matrices y [protected] |
matrix::Matrices z [protected] |
The documentation for this class was generated from the following files:
